


























SEO a renderowanie JavaScript - jak sprawdzić oraz rozwiązać problemy

Spis treści:
- Czym jest JavaScript i dlaczego wykorzystuje się go na stronach internetowych?
- Wpływ obecności JavaScript na SEO strony
- WRS (Web Rendering Service)
- Ograniczone zasoby Google
- Zasoby zewnętrzne – czy nie mamy na nie wpływu?
- Jak zabezpieczyć się przed problemami JS?
- Narzędzia zewnętrzne do analizy renderowania
- Różne sposoby renderowania stron
- Podsumowanie
Czym jest JavaScript i dlaczego wykorzystuje się go na stronach internetowych?
JavaScript to nieodzowny element programowania webowego. Dostrzegamy w DevaGroup wzrost jego użycia w serwisach internetowych - podczas wykonywania audytów SEO. Jest on często używanym językiem programowania, który ma za zadanie zapewnić możliwość dynamicznego generowania danych na stronie internetowej. Nadal podstawowym filarem budowy strony są HTML oraz CSS, ale bez obecności JS nie byłoby w/w dynamiki w wyświetlaniu danych.
W jaki sposób implementujemy JS na stronach www?
Jednym z przykładów mogą być serwisy informacyjne, które prowadzą na żywo relacje z wydarzeń. Jak widzimy poniżej, działa tam właśnie automatyczne odświeżanie.
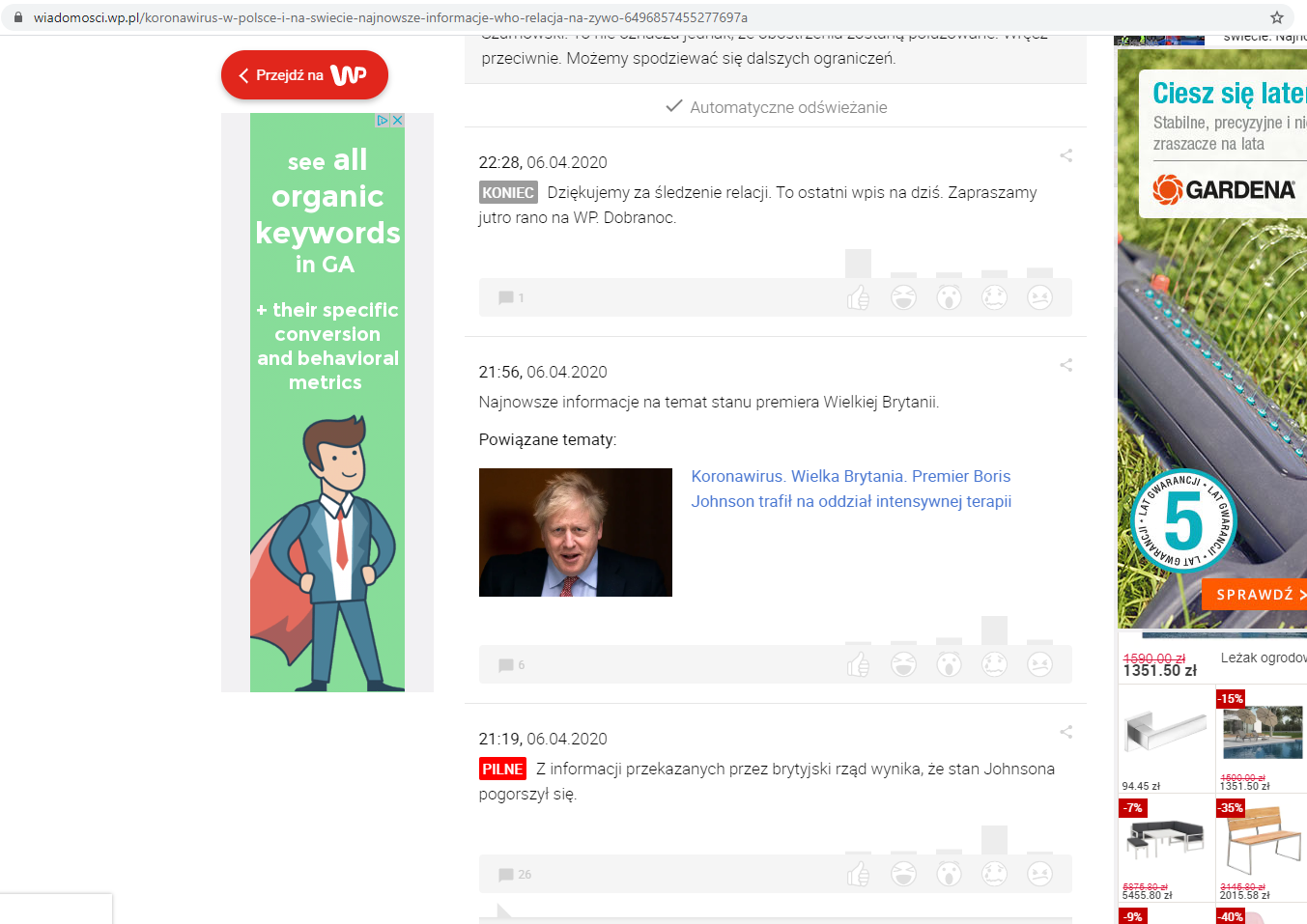
Źródło: www.wiadomosci.wp.pl
Inne zastosowanie JavaScript to relacje na żywo z imprez sportowych (np. mecze piłkarskie) czy też działające w czasie rzeczywistym moduły komentarzy. Wraz z ewolucją technologii stron www liczba zastosowań języka JS wciąż rośnie. Oprócz generowania dynamicznej treści używa się go także do pobierania danych z działań na stronie i przesyłania ich do narzędzi analitycznych. W jaki sposób są umieszczone skrypty JS w kodzie strony?
Skrypty JS mogą być umieszczone:
- wewnątrz kodu HTML danej podstrony

- w osobnym pliku *.js (wtedy na podstronie znajduje się odnośnik)

- na zewnętrznym serwerze (np. kody śledzenia czy też widżety social media)
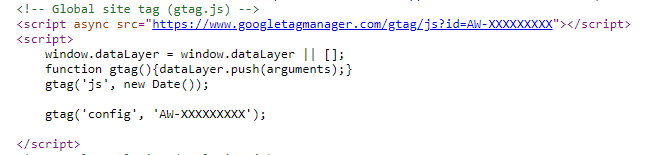
Najmniej kontroli mamy nad skryptami, które są umieszczone na zewnątrz serwera (skrypty osób trzecich). Na ich budowę i sposób działania właściwie nie mamy wpływu. Na usprawnienie ich wczytywania już tak – poruszę ten temat w dalszej części artykułu. Teraz przejdźmy natomiast do tego, jaki wpływ na SEO mają kody JS.
Wpływ obecności JavaScript na SEO strony
Zapewne niejednokrotnie słyszysz, że JS na stronie internetowej ma negatywny wpływ na SEO albo nawet uniemożliwia odczytanie serwisu. Nie jest to jednak prawda. Nie istnieje jednoznaczna zależność między obecnością kodów JS a brakiem możliwości renderowania treści. Google wciąż udoskonala swoją technologię i deklaruje zdolność wczytywania większości kodów JS. Jeśli chcesz być na bieżąco z tym, w jaki sposób Google odczytuje strony z użytą na nich technologią JS, zapraszam do obejrzenia filmu bezpośrednio od pracownika Google:
Skoro Google radzi sobie z JS, to czemu wciąż mówi się o tym, że to problem w SEO? Powodem tego podejścia jest fakt, iż Google nie zawsze jest w stanie odczytać ten skrypt prawidłowo.
Sytuacje problematyczne pojawiają się w dwóch przypadkach:
- Google nie jest w stanie odczytać kodu JS
- Google nie zdąży wczytać w pełni kodu JS
Z tych dwóch powodów rzeczywiście mogą zaistnieć problemy z SEO strony. Powyższe kłopoty wyszukiwarki wynikają ze sposobu działania systemu odpowiedzialnego za renderowanie i indeksowanie w Google.
Myślę, że w tym momencie warto poruszyć temat WRS (web rendering service) i tego, jak działa proces renderowania stron.
WRS (Web Rendering Service)
Czym jest WRS? Jest to system, który odpowiada za pobieranie oraz renderowanie stron internetowych. W jaki sposób działa WRS? Google opiera swój system renderowania na silniku przeglądarki internetowej Chrome. Wielokrotnie słyszę, że aby poznać sposób renderowania, wystarczy pobrać Chrome w wersji 41. Nie jest to prawdą. Dlaczego? Jest to informacja nieaktualna. Już w maju 2019 Google poinformowało, że WRS opiera się na najnowszej stabilnej wersji Chromium – www.webmasters.googleblog.com/2019/05/the-new-evergreen-googlebot.html. Co ważne, zadeklarowano stałą aktualizację Chromium używanej do tego celu wraz z pojawieniem się kolejnych stabilnych wersji. Dlatego nazwano tego Googlebota “evergreen Googlebot”.
Wróćmy tutaj do sposobu wczytywania stron omówionego w zamieszczonym wyżej filmie. W przypadku stron z czystym HTML i JS funkcjonuje to według schematu:
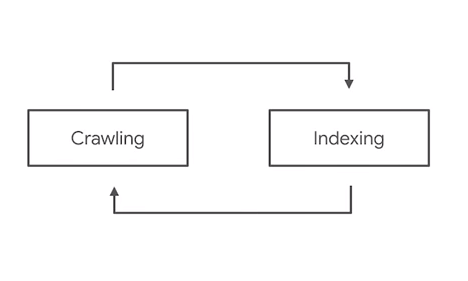
Źródło: www.youtube.com/watch?v=LXF8bM4g-J4
Google odczytuje zawartość kodu strony w HTML i od razu indeksuje jej zawartość. Inaczej jest jednak w przypadku stron z kodem JS. W takiej sytuacji kroków jest więcej.
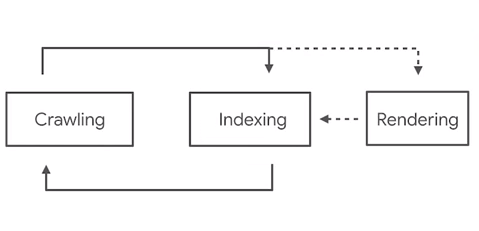
Źródło: www.youtube.com/watch?v=LXF8bM4g-J4
Google działa następująco: wczytuje zawartość generowaną w HTML i indeksuje ją, a niezależnie od tego pobiera zawartość plików JS i stara się ją odczytać. To właśnie w tym momencie mogą pojawić się problemy z wczytaniem pliku, jak i z SEO serwisu.
Głównymi powodami kłopotów z wczytaniem obsługiwanego przez Google kodu JS – jak podaje Google w swoich materiałach video – są:
- blokady dostępu do plików *.js (np. w robots.txt)
- zbyt długi czas wczytywania zasobu i porzucenie przez Google próby odczytania go.
Źródło: www.youtube.com/watch?v=rq8sFkl0KnI
O ile w przypadku blokady plików JS w robots.txt sprawa jest prosta – nie wolno tego robić, o tyle w przypadku przekroczenia budżetu renderowania temat jest bardziej rozbudowany. Dlaczego tak się dzieje, że Google wyznacza limity? O tym w kolejnej części tego artykułu.
To, o czym warto jeszcze wspomnieć na tym etapie, to fakt, iż Google wciąż rozwija swoją usługę i stara się rozpoznać zasoby, które nie mają wpływu na renderowanie serwisu. Oznacza je, a później, na podstawie swoich wcześniejszych analiz, wyklucza z analizowania. To oznacza, iż nie wszystkie zasoby strony są pobierane i odczytywane przez Google. Czynność ta ma ograniczyć niepotrzebne marnowanie zasobów sprzętowych wyszukiwarki.
Ograniczone zasoby Google
Rozwińmy zatem temat ograniczeń sprzętowe. Google nie może sobie pozwolić na czekanie w nieskończoność na wczytanie zasobów, ponieważ hamowałoby to cały proces i zmniejszałoby liczbę renderowanych stron internetowych. Renderowanie uszkodzonych stron mogłoby zaburzyć działanie całego systemu.
Co Google podaje jako powody przerwania przetwarzania JS, by chronić swoje zasoby?
Oficjalne powody to:
- zbyt duża liczba pobieranych zasobów,
- zbyt duża objętość zasobów,
- brak cache dla zasobów strony (według Google ma to istotny wpływ na czas wczytywania strony i przerwanie procesu).
Informację, w jaki sposób Google podchodzi do renderowania JS i oszczędzania swoich zasobów, podano w poniższym filmie:
Pracownik Google wskazuje w nim również powody skrajnych problemów z renderowaniem. Dowiadujemy się, że Google wstrzymuje renderowanie, gdy:
- uszkodzony plik JS zapętla się,
- używamy JS do cloakingu (wyświetlania innej treści Google, a innej użytkownikom),
- na stronie znajdują się tzw. koparki kryptowalut.
Zasoby zewnętrzne – czy nie mamy na nie wpływu?
Na początku artykułu wspomniałem o sposobach implementacji kodu JS na stronie. W przypadku kodu dodanego do HTML oraz linkach wewnętrznych, mamy wpływ na budowę zasobów i możemy je optymalizować czy też łączyć ze sobą lub rozdzielać. W przypadku, gdy to zewnętrzne zasoby strony spowalniają jej rendowanowanie – polecam poszukać informacji o tzw. third-party JavaScript. Gdy wczytywanie HTML jest blokowane i jest to spowodowane zbyt długim wczytywaniem zasobów, możemy poprzez specjalne atrybuty odłożyć to na okres po wczytaniu pełnego kodu HTML.
Dlaczego warto stosować atrybuty async i defer?
Przy powolnym wczytywaniem zasobów, jak wyjaśniłem, istnieje ryzyko, że Google przerwie proces renderowania i nie dotrze do dalszej części kodu HTML – dlatego włąśnie warto odłożyć w czasie wczytywanie skryptów, by zapewnić najpierw dotarcie do kodu HTML i treści w nim zawartej.

Źródło: www.web.dev/efficiently-load-third-party-javascript/
Wybór w/w atrybutów zależy od sytuacji i miejsca, w którym je wdrażamy. Aby dowiedzieć się, jaki atrybut jest najkorzystniejszy i kiedy, omówimy teraz ich działanie.
Async
Skrypt z atrybutem async uruchamiany jest przy pierwszej okazji, gdy zakończone jest pobieranie strony, ale jeszcze przed załadowaniem tzw. load event. Ważną informacją jest fakt, że skrypty takie mogą nie być wczytywane w kolejności, w jakiej są ulokowane w kodzie HTML.
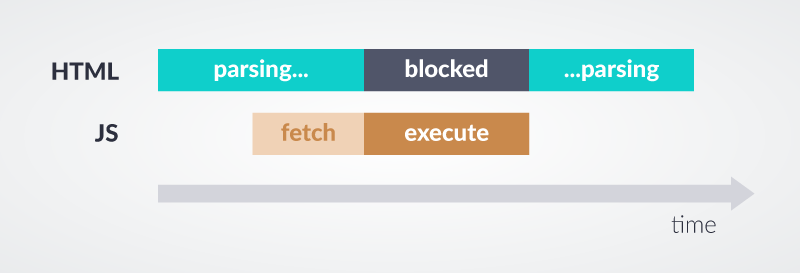
Źródło: www.web.dev/efficiently-load-third-party-javascript/
Użyj atrybutu async, jeśli zależy Ci, by skrypt był uruchamiany podczas ładowania strony.
Defer
Skrypt z atrybutem defer uruchamiany jest już po analizie składni HTML, a przed wykonaniem DOMContentLoaded. Ważną informacją jest fakt, że skrypty dzięki temu atrybutowi mogą być wczytywane w kolejności, w jakiej są ulokowane w kodzie HTML. Atrybut ten zapewnia kolejność wykonywania skryptów (zgodnie z ich miejscem w HTML) oraz zapobiega blokowaniu analizatora składni HTML.
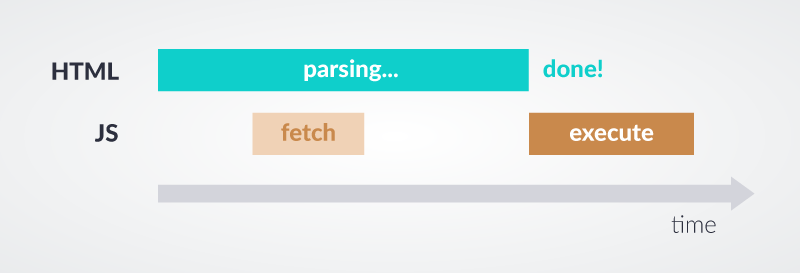
Źródło: www.web.dev/efficiently-load-third-party-javascript/
Użyj atrybutu defer, jeśli wczytywanie zasobu nie ma wpływu na ładowanie strony i możesz go spokojnie doładować potem. Jednym z przykładów jest takiego zasobu jest odtwarzacz video.
Więcej na temat tych atrybutów można przeczytać pod adresem: www.web.dev/efficiently-load-third-party-javascript/
Jak zabezpieczyć się przed problemami JS?
Najbezpieczniejszym rozwiązaniem jest wczytywanie zawartości contentowej oraz linkowania wewnętrznego bez użycia JS. W takiej sytuacji Google wczyta i zaindeksuje treść w pierwszym kroku, a potem będzie wczytywało zawartość generowaną przez JS. W sytuacji, gdy nastąpi kłopot z czytaniem kodu JS – mamy przynajmniej zaindeksowaną treść i linki wewnętrzne.
Tutaj warto również pamiętać, że Google działa na silniku przeglądarki Chrome, ale nie wygląda to tak samo, jak w przypadku korzystania z niej jako użytkownik. Jeśli jakaś ważna zawartość serwisu podawana jest wyłącznie po wykonaniu scrolla, zaakceptowaniu ciasteczek czy też przy dopasowaniu do lokalizacji użytkownika – Google nie będzie mogło tego odczytać. Nie kliknie przycisku, ani nie przewinie niżej.
Rozwiązaniem dla stron z użyciem JS są z pozoru proste wytyczne:
- jeśli masz na stronie JS, to staraj się, by treści i linki były wczytywane po HTML – linki wewnętrzne z użyciem <a href=”/adres”>link</a> (a nie tylko samym onclick),
- używaj cache dla zasobów, aby ograniczyć ich wpływ na budżet renderowania,
- stosuj asynchroniczne wczytywanie zasobów zewnętrznych,
- w sytuacji, gdy JS wpływa jednak na treść i ważne elementy strony – nie blokuj ich przed Googlebotem,
- adresy generuj w sposób możliwy do odczytania – adresy podstron domena.pl/podstona-serwisu, a nie domena.pl#podstrona.
Jak sprawdzić, czy JavaScript na stronie zaburza SEO?
Najpewniejszym sposobem na weryfikację strony w tym aspekcie jest sprawdzenie efektów renderowania w Google Search Console. Poprzez inspekcję adresu URL możemy sprawdzić, w jaki sposób Google „widzi” naszą stronę.
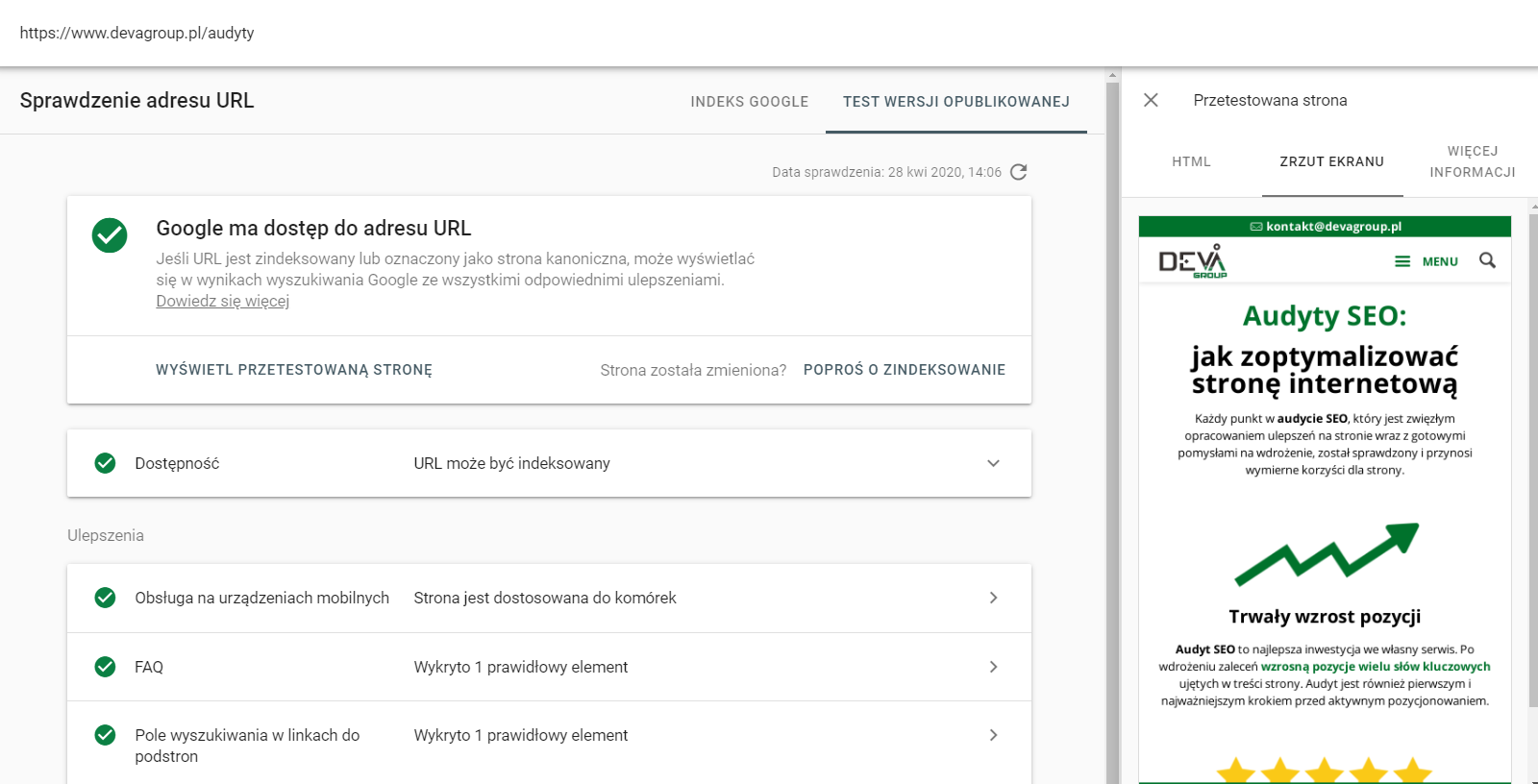
Dodatkowo możemy zweryfikować kod HTML i sprawdzić, czy pojawiają się tam treści oraz linki z naszej strony.
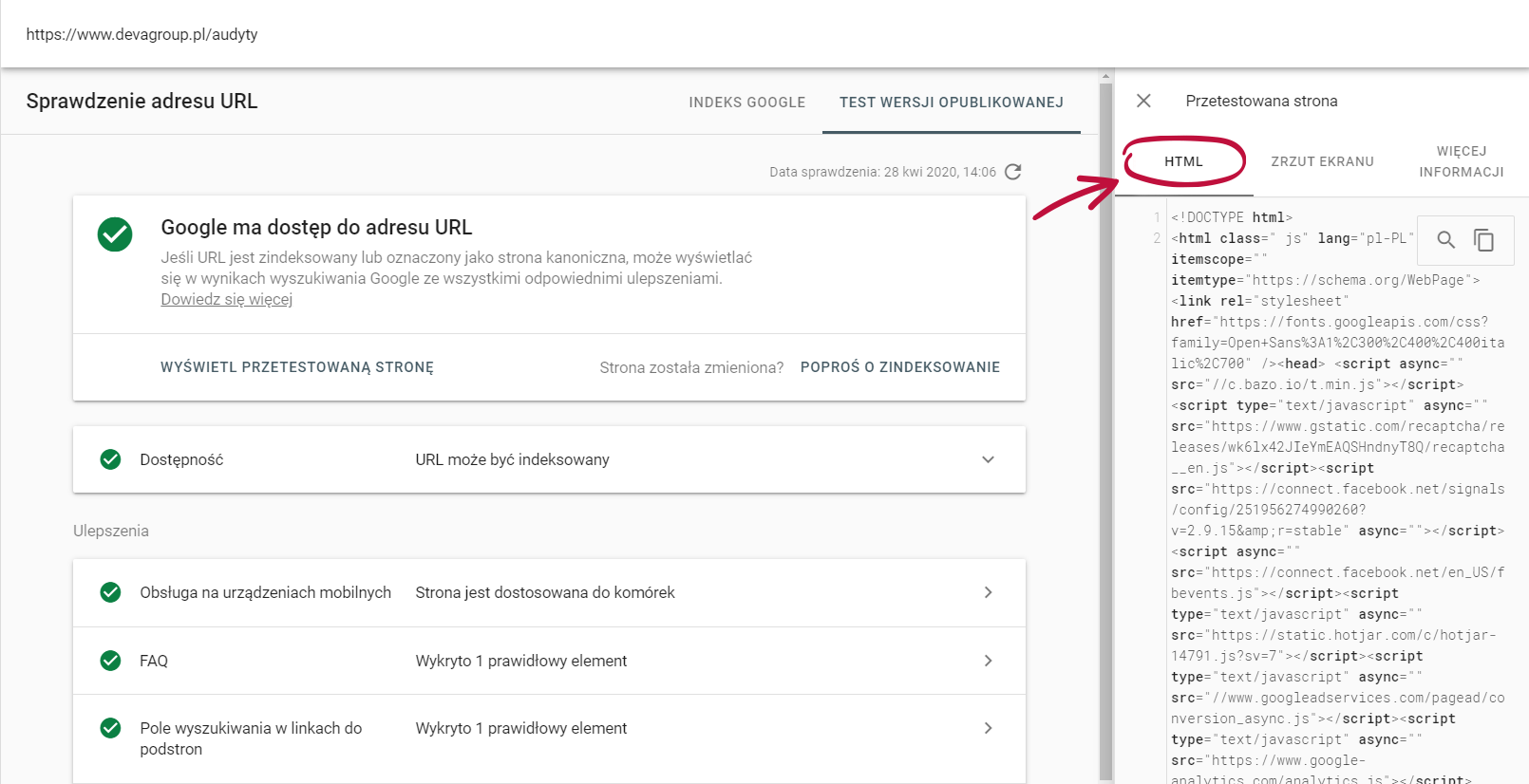
W kodzie tym warto prześledzić, czy znajduje się tam treść serwisu. Możemy zrobić to, używając komendy „site:” w wyszukiwarce.
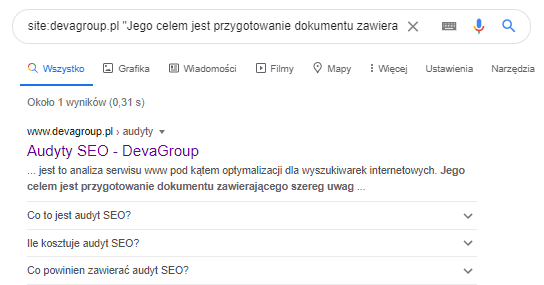
Technika ta jednak nie jest tak dokładna, jak użycie w tym celu inspekcji adresu URL. W sytuacji, gdy nie mamy dostępu do GSC, możemy analizować renderowanie JS na stronie z użyciem narzędzi zewnętrznych. Poniżej przedstawię dwa narzędzia, którymi najczęściej badam stronę w kontekście jej renderowania.
Narzędzia zewnętrzne do analizy renderowania
Przed sprawdzeniem renderowania strony internetowej w specjalnych oprogramowaniach należy pamiętać, iż nie są to narzędzia Google. Nie mamy więc pewności, co do ich skuteczności. Z mojego doświadczenia wynika jednak, że często wykazują one wiele błędów i ma to przełożenie na rzeczywistość. Stosuję je do wstępnej analizy (np. strony na serwerze testowym). W sytuacji, gdy nie widać tam problemów – wykonuję jeszcze ostateczną analizę po inspekcji w GSC. Poniżej omawiam, z jakich narzędzi można w tym celu skorzystać.
Screaming Frog
Symulacji renderowania można dokonać z użyciem Screaming Frog. Warto tam ustawić max oczekiwania na zasoby 5s (to takie logiczne i standardowe oczekiwanie). Google okres oczekiwania uzależnia od wielu czynników, ale warto skracać go do minimum, ponieważ wtedy ograniczamy możliwość przerwania renderowania (z powodu zbyt długiego okresu oczekiwania).
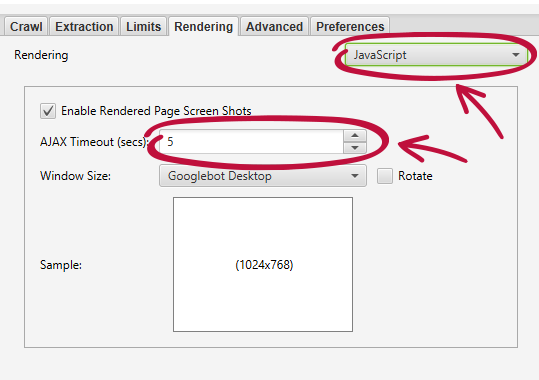
Po wysłaniu robota SF i otrzymaniu wyniku warto sprawdzić nie tylko podgląd strony, ale i zasoby zablokowane, które znajdują się po lewej na poniższym screenie.
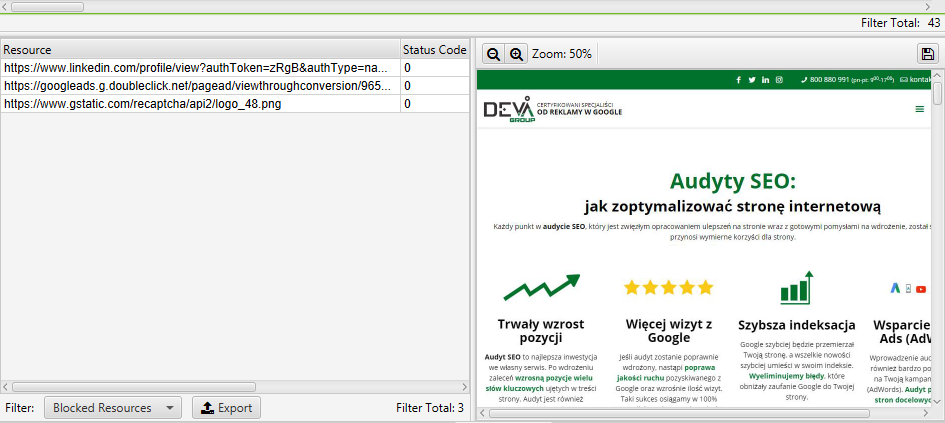
Jeśli znajdują się tam jakieś zasoby, które mają wpływ na budowę oraz treści strony – należy zweryfikować, dlaczego nie ma do nich dostępu.
TechnicalSEO
Kolejnym rozwiązaniem, z którego korzystam na co dzień, jest narzędzie online –www.technicalseo.com/tools/fetch-render/. Tutaj również warto ustawić 5 s oczekiwania oraz uwzględniać plik robots.txt .

Po wyrenderowaniu strony widzimy kod (zarówno HTML, jak i kod wyrenderowany na koniec) oraz podgląd strony.
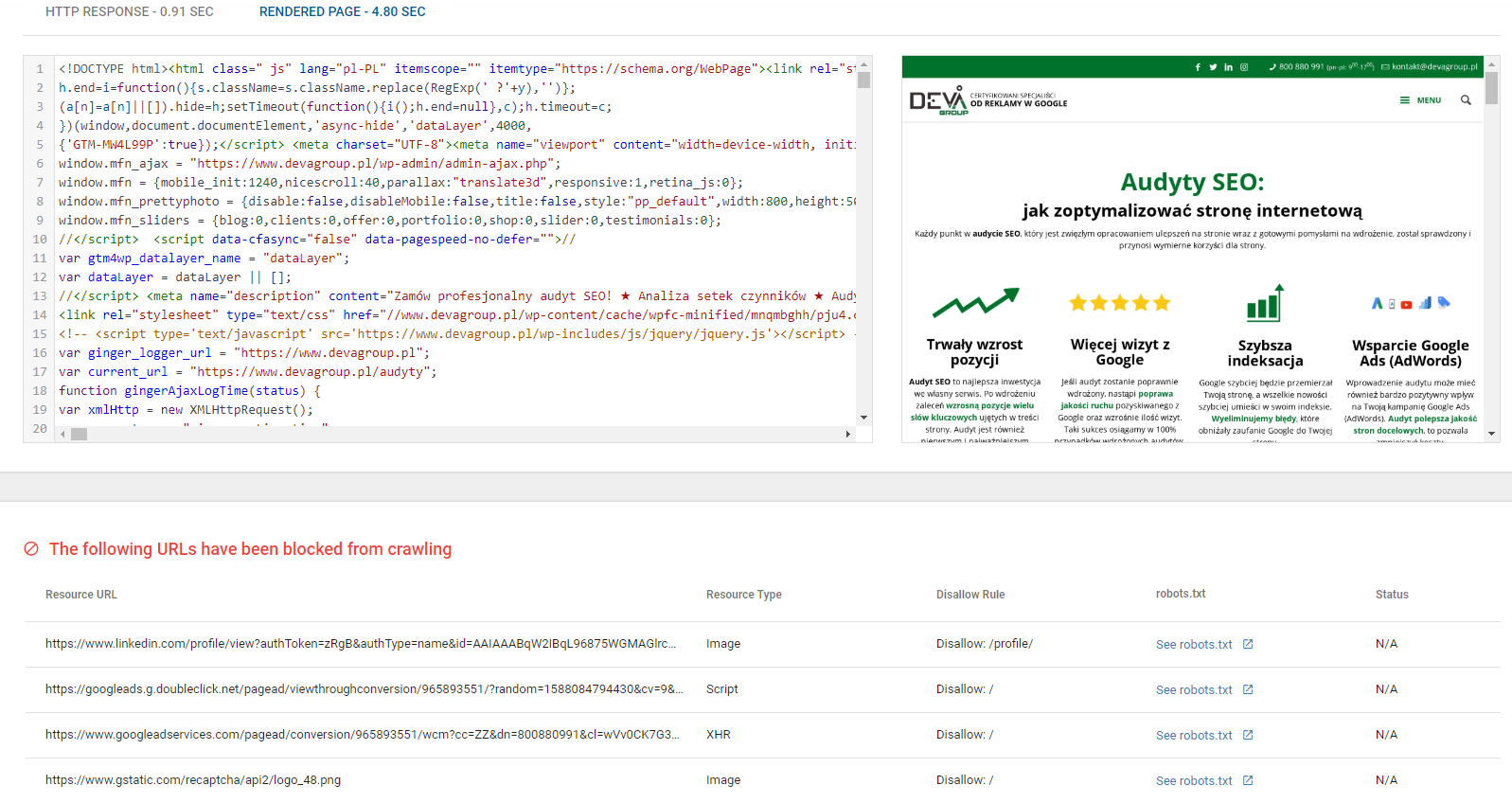
Na dole powyższego screena możemy dostrzec informacje na temat zasobów, do których nie było dostępu. Podobnie jak w przypadku wcześniej omawianego narzędzia, tutaj również możemy sprawdzić, czy nie blokujemy ważnego dla działania serwisu zasobu.
Różne sposoby renderowania stron
W przypadku omawiania wpływu SEO na widoczność stron nie należy zapominać o podziale na różne techniki renderowania. Odpowiedni wybór techniki ma wielki wpływ na efekty w przypadku stron z dużą ilością kodu JS.
Renderowanie po stronie klienta
Dotychczas standardem było renderowanie po stronie klienta (client-side rendering). Co to znaczy? Zarówno przeglądarka, jak i GoogleBot mają za zadanie odczytać stronę, jej zasoby i dokonać jej renderowania. Właśnie w tym momencie ogromny wpływ na poprawność budowy zasobów ma ich wielkość, zablokowanie do nich dostępu itd. Nie jest to jednak jedyna metoda renderowania stron internetowych.
Renderowanie po stronie serwera
Kolejnym podejściem do tego tematu jest wykonywanie renderowania po stronie serwera (server-side rendering). Jest to rekomendowane rozwiązanie, gdy Google Bot nie radzi sobie z renderowaniem strony po stronie klienta.
Zasady działania tego rozwiązania są następujące:
- Renderowanie dokonywane jest w pełni po stronie serwera.
- Serwer przesyła do przeglądarki (oraz do Google Bota) zawartość w postaci czystego HTML-a.
- Google Bot oraz różnego rodzaju boty narzędzi social media nie mają problemu z odczytaniem zawartości.
Warto wspomnieć również, że rozwiązanie to wpływa bardzo na prędkość. Serwer przesyła do pamięci podręcznej przeglądarki raz pobrane dane i potem nie ma już potrzeby odpytywania ponownie serwera.
Więcej informacji o wdrożeniu SSR na różnych silnikach:
- Angular – www.angular.love/2018/12/28/o-server-side-rendering-w-angular/
- React – www.nafrontendzie.pl/server-side-rendering-react-1-wprowadzenie
- Node.js – www.uszanowanko.pl/prezentacja/node-js-server-side-rendering-1
Renderowanie dynamiczne
Jeszcze innym sposobem na renderowanie jest zastosowanie technologii zwanej „renderowaniem dynamicznym”. W tym przypadku tworzymy taką hybrydę, która łączy dwie powyższe metody.
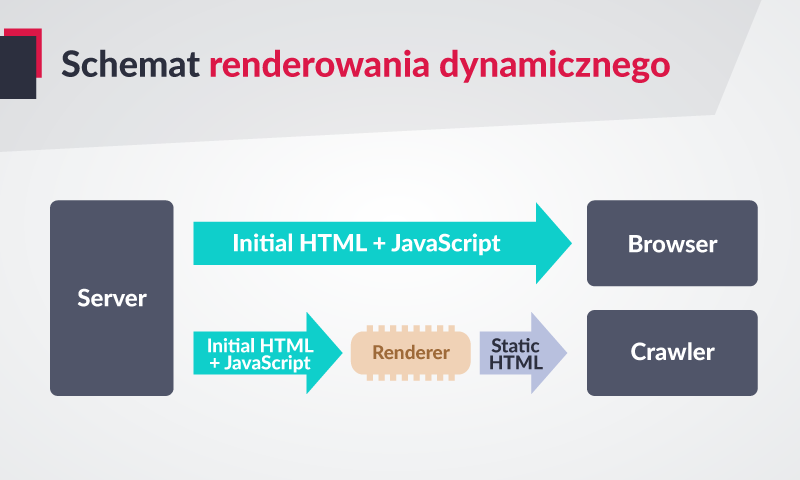
Źródło: www.developers.google.com/search/docs/guides/dynamic-rendering
W zależności od tego, kto wysyła zapytanie o adres, wybierana jest jedna z dwóch ścieżek:
- Jeśli stronę wywołuje użytkownik w przeglądarce – strona jest ładowana w tradycyjny sposób, czyli z użyciem renderowania po stronie klienta. Przekazujemy w pełni funkcjonalną stronę z wszelkimi dynamicznymi elementami opartymi o JS.
- Jeśli wywołanie wyszło od Google Bota (oraz wszelkich innych botów np. social media), strona jest renderowana po stronie serwera. Boty utrzymują stronę statyczną w HTML i mogą dzięki temu bez problemu odczytać jej zawartość.
Brzmi trochę jak oszukiwanie Google? Co innego robimy dla użytkownika, a co innego dla Google? Tylko z pozoru. Pamiętaj, że ideą tego rozwiązania jest podawanie tej samej treści, tylko na różne sposoby. Nie okłamujemy bota, a raczej pomagamy mu zrozumieć nasz serwis.
Rozwiązanie to jest rekomendowane także przez Google – więcej o tym pod adresem dokumentacji Google (www.developers.google.com/search/docs/guides/dynamic-rendering) oraz w poniższym filmie:
Więcej informacji na temat możliwych technologii renderowania stron możesz sprawdzić pod adresem: www.developers.google.com/web/updates/2019/02/rendering-on-the-web. Polecam również zapoznanie się podstawowymi informacjami dotyczącymi SEO w kontekście technologii JS: www.developers.google.com/search/docs/guides/javascript-seo-basics
Omawiając renderowanie dynamiczne, nie można zapomnieć o coraz bardziej popularnym zastosowaniu PWA (Progressive Web Apps) i związanych z tym zasadach, których należy przestrzegać w kontekście SEO.
PWA (Progressive Web Apps)
PWA (Progressive Web Apps) to coraz popularniejszy trend w produkcji aplikacji internetowych. Technologia ta jest hybrydą zwykłych stron internetowych i funkcjonalności aplikacji mobilnych. Możemy na taką stronę wejść tak jak na tradycyjny serwis a potem już zaczyna się to, co umożliwia PWA – możliwość pobrania aplikacji do ekranu głównego telefonu, aktualizacje informacji w tle i możliwość działania w trybie offline. To tylko kilka podstawowych zalet wdrożenia PWA.
Nie będę dokładnie opisywał idei i zasady działania tej technologii, ale zapraszam do zapoznania się z tymi informacjami pod adresem – www.medium.com/@deepusnath/4-points-to-keep-in-mind-before-introducing-progressive-web-apps-pwa-to-your-team-8dc66bcf6011.
Przejdźmy do najważniejszych aspektów, na które musimy zwracać uwagę, by PWA było SEO friendly. Oto konieczne kroki:
- Zapewniamy Google możliwość renderowania i indeksowania.
- Stosujemy prawidłowe i przyjazne adresy URL (chodzi o te same zasady budowania podstron na unikalnych adresach domena.pl/podstrona, co w przypadku standardowych stron w HTML)
- Używamy natywnych elementów HTML (np. <button> zamiast <div class=”button”>).
- Stosujemy progresywne ulepszanie.
- Dbamy o wydajność.
- Podajemy takie same treści użytkownikowi oraz robotom Google.
- Stosujemy atrybut „scrset” dla zdjęć, by dopasować ich odpowiednie rozmiary.
- Korzystamy z pamięci podręcznej.
Warto również stosować dodatkowe znaczniki:
- dane strukturalne Schema.org,
- tagi Open Graph i Twitter Card.
Zapraszam również do zapoznania się z informacjami, które przekazuje Google w filmie:
Podsumowanie
JavaScript jest nieodzowną częścią technologii budowy stron i nie warto go demonizować. Najbezpieczniej jest generować treść bezpośrednio w kodzie HTML, a zasoby skonfigurować tak, by nie blokowały procesu renderowania elementów HTML. Jeśli mimo optymalizacji i przebudowania strony, Google nadal nie radzi sobie z zawartością zbudowaną przy użyciu JS – warto rozważyć zmianę technologii renderowania treści. Czasami jedynym wyjściem jest podanie czystego kodu HTML, który jest wynikiem renderowania po stronie serwera. Powodzenia w analizowaniu serwisu i weryfikacji wpływu JS na SEO Twojej strony internetowej! Jeśli masz problemy w tym aspekcie – daj znać, a znajdziemy rozwiązanie.






